

4









| Thumbs Up/Down |
| Received: 89/0 Given: 126/0 |
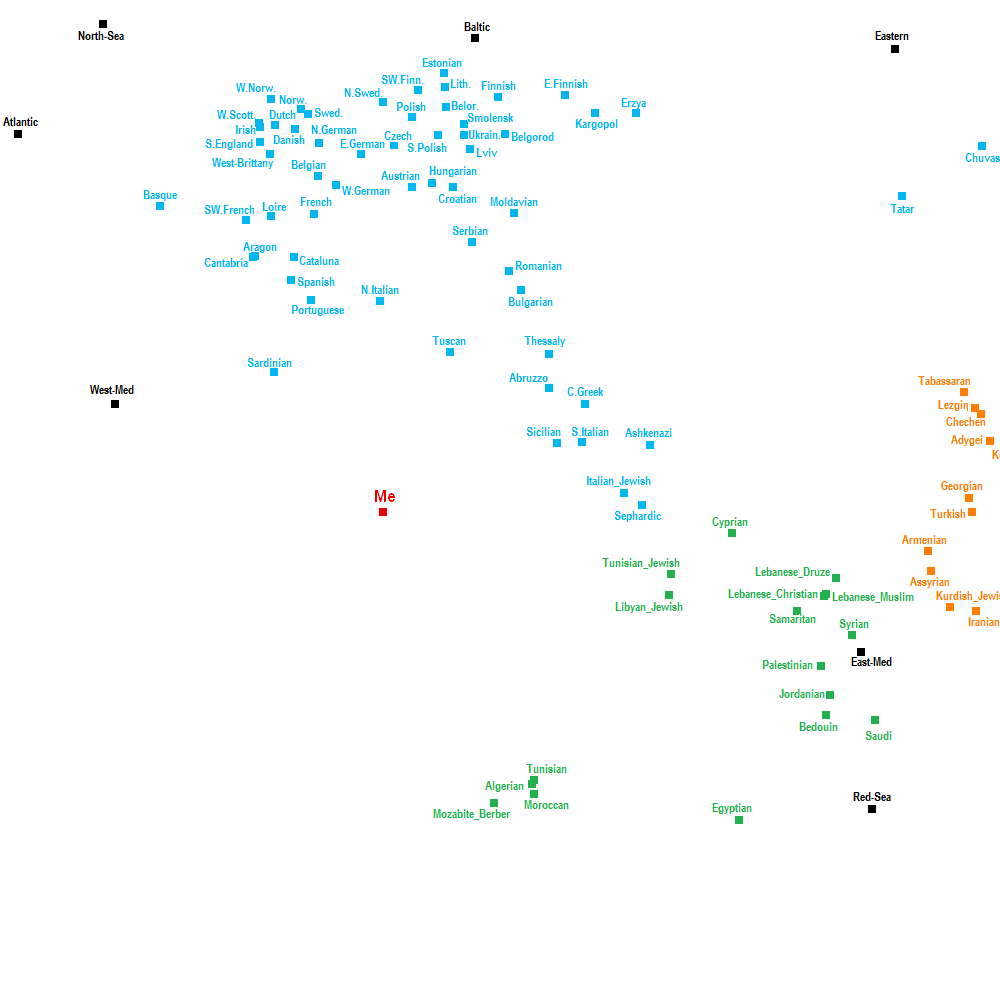
I wonder if the trends (WestMed, Atlantic, North Sea, ...) were arbitrarily placed on the map ...
Because the closest shared population with oracle / oracle4 is Spanish Galicia while on the map it is Sicilian.
Eurogenes EUtest V2 K15
Table
Oracle
Admix Results (sorted):
# Population Percent
1 North_Sea 21.43
2 West_Med 17.62
3 Atlantic 17.47
4 East_Med 15.78
5 Red_Sea 9.58
6 Sub-Saharan 7.08
7 Northeast_African 5.23
8 Eastern_Euro 3.71
Single Population Sharing:
# Population (source) Distance
1 Spanish_Galicia 14.65
2 Portuguese 14.85
3 Spanish_Extremadura 15.2
4 North_Italian 15.97
5 Spanish_Murcia 16.29
6 Tuscan 16.54
7 Spanish_Castilla_Y_Leon 17.03
8 Spanish_Cataluna 17.85
9 French 18.82
10 Spanish_Andalucia 18.96
11 West_Sicilian 18.97
12 Spanish_Castilla_La_Mancha 19.4
13 Spanish_Valencia 19.6
14 Spanish_Cantabria 19.96
15 Greek_Thessaly 20.33
16 Italian_Abruzzo 20.39
17 Ashkenazi 21.04
18 Algerian 21.13
19 Spanish_Aragon 21.19
20 East_Sicilian 21.23
Oracle 4
Least-squares method.
Using 1 population approximation:
1 Spanish_Galicia @ 15.516834
2 Portuguese @ 15.740553
3 Spanish_Extremadura @ 16.258934
4 North_Italian @ 16.502321
5 Spanish_Murcia @ 17.444559
6 Tuscan @ 17.493948
7 Spanish_Castilla_Y_Leon @ 18.508312
8 Spanish_Cataluna @ 19.138771
9 French @ 20.262537
10 Spanish_Andalucia @ 20.640858
11 West_Sicilian @ 21.084824
12 Spanish_Castilla_La_Mancha @ 21.222713
13 Spanish_Valencia @ 21.307306
14 Spanish_Cantabria @ 21.900888
15 Greek_Thessaly @ 22.142914
16 Italian_Abruzzo @ 22.438175
17 Serbian @ 23.138306
18 Spanish_Aragon @ 23.256512
19 Ashkenazi @ 23.579531
20 East_Sicilian @ 23.806423
Map





| Thumbs Up/Down |
| Received: 15,680/315 Given: 8,909/358 |
You're right between the Maghreb and SW Europe.Originally Posted by AtlantoMediterranean




| Thumbs Up/Down |
| Received: 10,991/64 Given: 20,238/16 |
Its probably the design layout, differing reference samples and mathematical approximations that slightly alters one's autosomal estimate and where you roughly correspond in each software.
My guess is probably because each author designed each software differently. Hence, there is a subtle, yet, noticeable discrepancy in each individual's respective result(s) on both the PCA and Oracles.
The most merciful thing in the world, I think, is the inability of the human mind to correlate all its contents. We live on a placid island of ignorance in the midst of black seas of infinity, and it was not meant that we should voyage far. The sciences, each straining in its own direction, have hitherto harmed us little; but some day the piecing together of dissociated knowledge will open up such terrifying vistas of reality, and of our frightful position therein, that we shall either go mad from the revelation or flee from the light into the peace and safety of a new dark age.
- H.P. Lovecraft



| Thumbs Up/Down |
| Received: 11,402/53 Given: 6,787/3 |
You have to look at the "distances", you match Galicia first but @15 which is a terrible match. If you had it @2 ok but in this case you need to look at better matches with multipop or mixmode, you ll see the ones with the closest distances will better represent your point, if a fit was @0 it would be exactly your point, but it's never the case (or very rarely).
Same answer for *****. Even 6 is not that great of a match and fitting will almost always better it. Just see those numbers as a precision.



| Thumbs Up/Down |
| Received: 2,993/91 Given: 1,103/118 |
you have to take in account the distances, a distance of 15 is very high, which means you are not at all close to them.
| Thumbs Up/Down |
| Received: 89/0 Given: 126/0 |
I misspoke.
I understood what distance means and that a long distance in single mode often means a mixture and that a long distance in mixed population can reveal a lack of reference population.
(In my case in single mode I always had distances of 8 to 18 points according to the calculator, with often very different populations in first place, including Sicilian, Spanish, Albanian ...). In short, I know very well that a long distance does not reflect reality, that's not my question.
What I do not understand is the alleged correlation between the data from Eurogenes K15 and the PCA, because logically the distances with the populations calculated by oracle should be found visually on the PCA, except it is not entirely accurate. So my questioning is only technical.
I will illustrate it with another example :
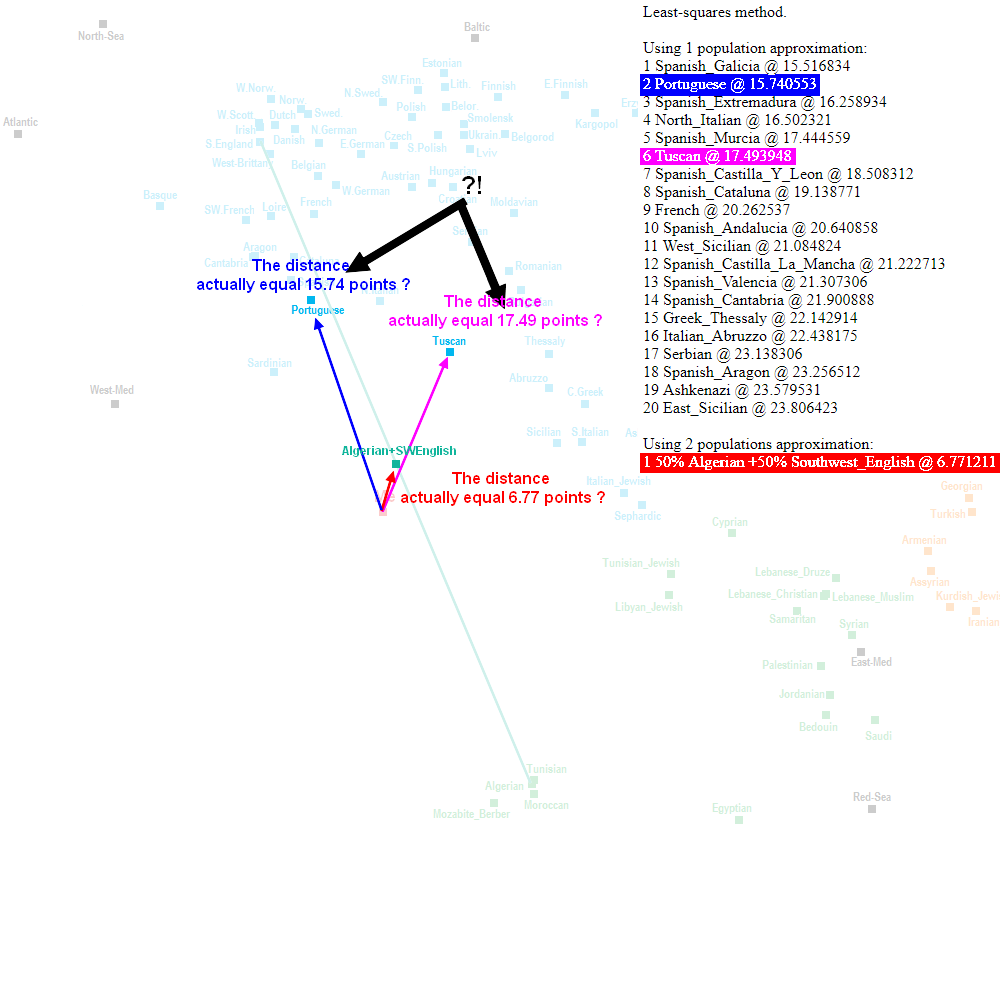


| Thumbs Up/Down |
| Received: 1,643/20 Given: 997/8 |
That's not really a PCA.
| Thumbs Up/Down |
| Received: 89/0 Given: 126/0 |
I do not know in any case the tool seems inaccurate in the results he wants to give.


| Thumbs Up/Down |
| Received: 548/62 Given: 94/32 |
| Thumbs Up/Down |
| Received: 15,680/315 Given: 8,909/358 |
@Weiss, you are outside the Eastern European cluster, however your placement may be a little bit different if you test at another company.
There are currently 1 users browsing this thread. (0 members and 1 guests)
 Posting Permissions
Posting Permissions



 Reply With Quote
Reply With Quote


Bookmarks