

0











| Thumbs Up/Down |
| Received: 5,382/129 Given: 6,047/229 |
He made wrong decision. Looking at this nMonte and ''modeling'' it looks like scam and inferior to gedmatch.Originally Posted by Vasconcelos

| Thumbs Up/Down |
| Received: 5,382/129 Given: 6,047/229 |
Lol and you must pay him for that crap.





| Thumbs Up/Down |
| Received: 15,697/315 Given: 8,913/358 |
Yes, the truth is that you can model yourself as almost anything, which doesn't mean you actually have that kind of ancestry. I can probably be modeled as Lithuanian + Serbian + Chuvash and things like that but in reality I don't have ancestors from those groups. How is that supposed to be more accurate? I prefer racial and geographic components, not just oracles.





| Thumbs Up/Down |
| Received: 17,446/194 Given: 8,253/117 |
G25 is better than Gedmatch, you just have to know how to use it. Once you've seen your results on Gedmatch that's it. You get no more value out of it. G25 is always being updated with new references to test.
Spoiler!


| Thumbs Up/Down |
| Received: 1,221/56 Given: 520/4 |
Could you add me. Thanks!
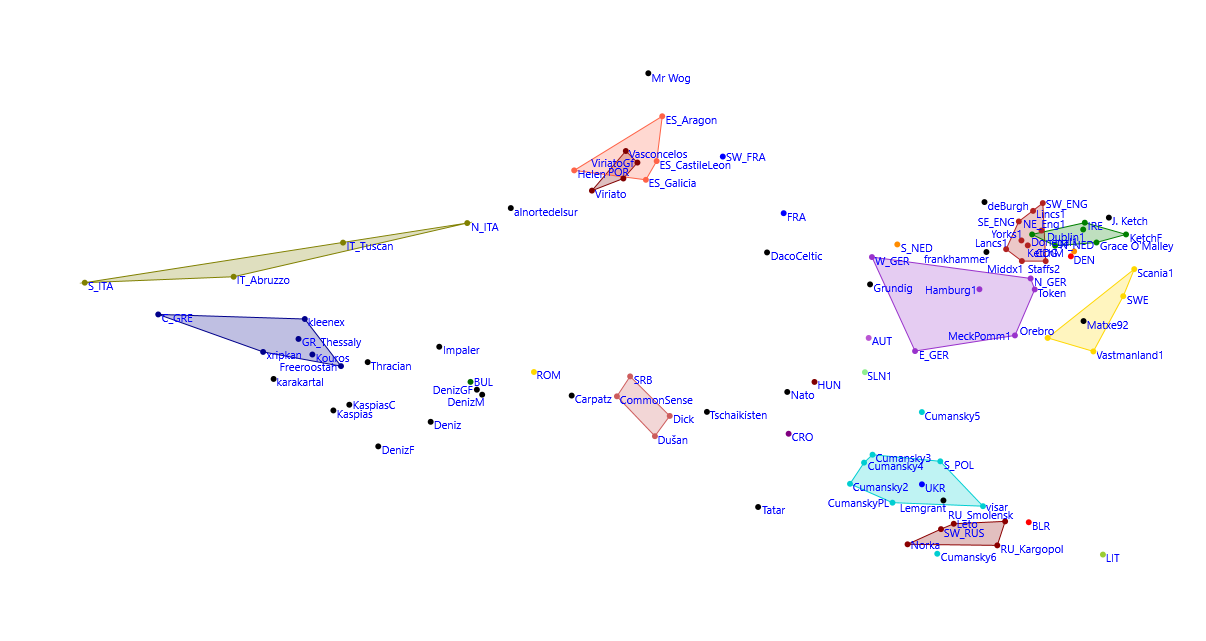
# Population Percent
1 East_Med 26.7
2 North_Atlantic 21.82
3 West_Med 19.44
4 Baltic 14.78
5 West_Asian 13.26
6 Red_Sea 3.35
7 Amerindian 0.64
Punt DNAL K15 Single Pop Sharing Tuscan 2.07
Mixed Mode Pop Sharing: 65.1% Tuscan+34.9% Greek_Thessaly @ 1.41
Eurogenes K 13 Single Pop Sharing Greek Thessaly 3.72
Mixed Mode Pop Sharing 69.5% South_Italian+30.5% Hungarian @ 2.56
MDLP K 16 Single Pop Sharing Greek (Greece) 3.62
Mixed Mode Pop Sharing: 58.3% Greek (Macedonia)+41.7% Italian (Bergamo)@ 2.5
| Thumbs Up/Down |
| Received: 17,446/194 Given: 8,253/117 |
Spoiler!

| Thumbs Up/Down |
| Received: 7,329/30 Given: 2,685/16 |
I wanted one year ago to add K47 to Gedmatch. They were nice "We will add for some time, no problem". I reminded them few times. But still nothing.
So it is also problem with Gedmatch guys...


| Thumbs Up/Down |
| Received: 4,256/88 Given: 4,999/482 |
What do you know about computation biology and data science in order to label it "shit"? Maybe there's a reason no one uses those calcs anymore (people here don't count, sorry)
Even if the algorith were exactly the same, the simple fact that it allows customisation and more/better references would already make it superior than those Gedmatch oracles. Gedmatch calcs were cool, but they are past now
Last edited by Vasconcelos; 02-10-2019 at 12:03 PM.

| Thumbs Up/Down |
| Received: 19,750/81 Given: 5,912/35 |
It's more for hypothesis testing, not exaclty but has use if used correctly.
| Thumbs Up/Down |
| Received: 7,329/30 Given: 2,685/16 |
I have some clues G25 is compatible with Eurogenes calculators. I will tell later maybe.
It is PCA made on K25 components of standard admixture calculator, not smartPCA on dataset with genomes.
Simply in every case someone orders coordinates Polako would have to convert his raw file to PLINK format, then merge with own G25 dataset, then convert it to Eigenstrat format, than make smartPCA, then find row with coordinates and then email it.
In case of PCA based on K25 calculator he does it using PAST in 30 seconds (and before test in DIY K25 calc of course for component breakdown but is automatic) , like I do for K36 runner. I don't believe he waste so much time, but maybe...
Last edited by Lucas; 02-10-2019 at 01:00 PM.
There are currently 1 users browsing this thread. (0 members and 1 guests)
 Posting Permissions
Posting Permissions

Bookmarks