

0








| Thumbs Up/Down |
| Received: 13/1 Given: 0/0 |
Really? Is that what you see?Originally Posted by Johnston

This gives me some interesting informations about you. Your overall characteristic position and mental abilities.
Bring back the stocks!



| Thumbs Up/Down |
| Received: 2/0 Given: 0/0 |
Why thank you for your insults.If you wish to look at yourself through a petri dish, and make divinations as if it were entrails of some sacrificial animal, then why should I bother?
| Thumbs Up/Down |
| Received: 13/1 Given: 0/0 |
No problem.
LEts make some more training.
This is a glas.
This is...
"johnston": It totaly does not resemble the other one, its totaly contradicting!"
OK, John...but its still a glas.
JOhn: Now, dont come me with that! Its totaly and absolutely something totaly different! there are riffles and all this!
Well John, but still its a glas.

Bring back the stocks!

| Thumbs Up/Down |
| Received: 84/1 Given: 28/2 |
I don't quite see where the results are conflicting.
Single Population Sharing (Eurogenes)
1 Estonian_Polish 4.36
2 Russian_Smolensk 4.88
3 Southwest_Russian 5.32
4 Belorussian 5.78
5 Lithuanian 5.92
| Thumbs Up/Down |
| Received: 2/0 Given: 0/0 |
Every different test comes up with different results, because the parameters are different, meaning different categories exist. What is the right classification outline? Too many to choose from...
| Thumbs Up/Down |
| Received: 84/1 Given: 28/2 |
Your genome exists objectively (raw data), and it can be described in many ways (tools), using a variety of coordinates. The diversity of classification arises from the fact that the world can be divided across many lines, but it doesn't change the biological reality.
For example, Europe can be divided into Southern and Northern, and Western and Eastern. One tool uses N-S, another W-E. You find on one tool that you have 80% N elements, and on another that you have 80% W elements. Considering them, you conclude that you are mostly North-Western. Yet another tool divides Europe into Atlantic, Uralic, Balkan, Iberian. You score 70% on Atlantic - which says a similar thing to the N-S and W-E tools, but in different words. Some tools zoom in further to look at smaller regions, some provide very complex coordinates.
Using many different tools and measuring your genome on different factors, you can conclude as to its nature. Some tools are not precise, but a good way to see the merit of a tool is too look at how reasonably it describes the general relation between various nations. Dodecad and Eurogenes are both quite reasonable in this aspect.
Single Population Sharing (Eurogenes)
1 Estonian_Polish 4.36
2 Russian_Smolensk 4.88
3 Southwest_Russian 5.32
4 Belorussian 5.78
5 Lithuanian 5.92


| Thumbs Up/Down |
| Received: 45/0 Given: 4/0 |
Playing around with the oracle program...
It's quite interesting that the most MENA chromossomes here correspond to Middle Eastern and African segments in Prof.McD's chromossome painting.
note: I choose the French Basques and the Mozabite for their isolation.
Chr 1
closest pop.
"Portuguese_D" "14.2074"
Admixture:
"79.7% French_Basque + 20.3% Saudis" "12.1738"
Chr 2
closest pop.
"French_Basque" "7.3552"
Admixture:
"94.5% French_Basque + 5.5% Thai" "4.7864"
Chr 3
closest pop.
"Portuguese_D" "5.5317"
Admixture:
"89.3% French_Basque + 10.7% Mozabite_H" "6.4663"
Chr 4
closest pop.
"French" "15.0621"
Admixture:
"79.7% French_Basque + 20.3% Saudis" "8.156"
Chr 5
closest pop.
"Spaniards" "6.851"
Admixture:
"93.7% French_Basque + 6.3% Mozabite_H" "4.6403"
Chr 6
closest pop.
"Portuguese_D" "8.9795"
Admixture:
"68.7% French_Basque + 31.3% Palestinian" "8.9145"
Chr 7
closest pop.
"Tuscan_H" "10.5433"
Admixture:
"66.9% French_Basque + 33.1% Palestinian" "3.6317"
Chr 8
closest pop.
"Portuguese_D" "13.3701"
Admixture:
"84.1% French_Basque + 15.9% Saudis" "4.7202"
Chr 9
closest pop.
"Spaniards" "6.6472"
Admixture:
"92.4% French_Basque + 7.6% Mozabite_H" "4.5216"
Chr 10
closest pop.
"Portuguese_D" "6.1778"
Admixture:
"90.7% French_Basque + 9.3% Mozabite_H" "6.7866"
Chr 11
closest pop.
"N_Italian_D" "13.4641"
Admixture:
"63.2% French_Basque + 36.8% Turkish_D" "11.3022"
Chr 12
closest pop.
"Portuguese_D" "4.7087"
Admixture:
"86.9% French_Basque + 13.1% Mozabite_H" "6.9508"
Chr 13
closest pop.
"Portuguese_D" "10.6544"
Admixture:
"74.8% French_Basque + 25.2% Yemenese" "7.4308"
Chr 14
closest pop.
"Portuguese_D" "15.8912"
Admixture:
"15.2% Mozabite + 84.8% TSI" "11.8635"
Chr 15
closest pop.
"North_Italian" "8.2135"
Admixture:
"57.1% French_Basque + 42.9% S_Italian_D" "6.3083"
Chr 16
closest pop.
"Sardinian" "18.0121"
Admixture:
"15.1% Mozabite + 84.9% Tuscan" "20.1251"
Chr 17
closest pop.
"Portuguese_D" "11.1998"
Admixture:
"18.5% Belorussian + 81.5% French_Basque" "5.4225"
Chr 18
closest pop.
"French_Basque" "9.1593"
Admixture:
"91.9% French_Basque + 8.1% Mozabite_H" "4.4645"
Chr 19
closest pop.
"O_Italian_D" "12.8235"
Admixture:
"17.2% Chuvashs_16 + 82.8% Tuscan" "8.3058"
Chr 20
closest pop.
"Sardinian" "6.7713"
Admixture:
"75% French_Basque + 25% Samaritians" "12.2127"
Chr 21
closest pop.
"French" "13.9238"
Admixture:
"50% French_Basque + 50% Irish_D" "9.8556"
Chr 22
closest pop.
"Portuguese_D" "17.3147"
Admixture:
"75.7% French_Basque + 24.3% Saudis" "10.4584"
Genome-wide
DodecadOracle(c(1.24, 41.69, 41.89, 0.61, 3.27, 0.01, 0, 0.63, 1.81, 3.34, 5.50, 0),mixedmode=T)
[1,] "17.4% Egyptans + 82.6% French_Basque" "5.2935"
[2,] "83.4% French_Basque + 16.6% Yemenese" "5.9582"
[3,] "82.3% French_Basque + 17.7% Palestinian" "6.0211"
[4,] "83% French_Basque + 17% Jordanians_19" "6.1969"
[5,] "82.8% French_Basque + 17.2% Lebanese" "6.3786"
[6,] "77.8% French_Basque + 22.2% Sephardic_Jews" "6.4303"
[7,] "15.6% Bedouin + 84.4% French_Basque" "6.4875"
[8,] "84% French_Basque + 16% Syrians" "6.8094"
[9,] "83.4% French_Basque + 16.6% Samaritians" "6.8172"
[10,] "88.8% French_Basque + 11.2% Mozabite_H" "7.0901"

| Thumbs Up/Down |
| Received: 19,762/81 Given: 5,912/35 |
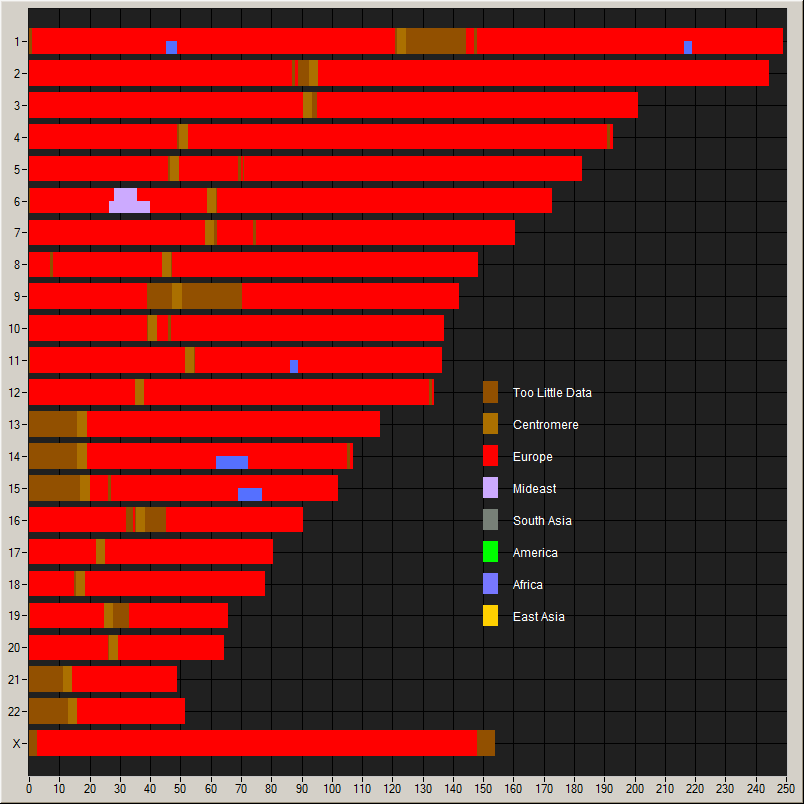
Top population by chromosome, too damn Irish
Chrom 15 I don't have any Uk cousins yet. Chrom 19 I share a large amount with a Shetlander.
- "Norwegian_D" "13.5248"
- "Cornwall_1KG" "5.0466"
- "Irish_D" "9.3998"
- "Dutch_D" "7.6135"
- "Irish_D" "14.1981"
- "Irish_D" "10.2298"
- "Irish_D" "7.7156"
- "Irish_D" "9.528"
- "Irish_D" "7.4474"
- "Irish_D" "13.965"
- "Irish_D" "10.8825"
- "Norwegian_D" "14.5978"
- "Irish_D" "15.1635"
- "Irish_D" "4.3421"
- "French" "5.5427"
- "Norwegian_D" "17.6212"
- "Norwegian_D" "9.739"
- "Irish_D" "13.9852"
- "German_D" "10.6425"
- "Irish_D" "5.4372"
- "Argyll_1KG" "6.7412"
- "Irish_D" "11.3448"
| Thumbs Up/Down |
| Received: 84/1 Given: 28/2 |
Here are mine:
Mixed_Slav_D = 5Code:1 FIN 9.667 2 Mixed_Slav_D 11.6598 3 Russian_D 11.4167 4 Hungarians 15.1674 5 FIN 14.6391 6 Mixed_Slav_D 13.0183 7 Polish_D 5.3431 8 Russian_D 6.5072 9 Hungarians 9.6005 10 Polish_D 12.7041 11 FIN 9.2743 12 Finnish_D 10.4971 13 Finnish_D 11.8036 14 Hungarians 11.1875 15 German_D 17.2096 16 Slovenian 7.1437 17 Hungarians 11.6839 18 Mixed_Slav_D 8.6327 19 Mixed_Slav_D 8.2442 20 Finnish_D 10.6054 21 Mixed_Slav_D 18.1396 22 Russian_D 10.219
Hungarian = 4
FIN = 3
Finnish_D = 3
Russian_D = 3
Polish_D = 2
Slovenian = 1
German_D = 1
With greater elaboration, since "Mixed Slavs" are a vague group, and FIN aren't strictly Finns.
Mixed_Slav = 11Code:1 [1,] FIN 9.667 [2,] German_D 15.2072 [3,] Swedish_D 17.9123 2 [1,] Mixed_Slav_D 11.6598 [2,] Russian_D 12.3579 [3,] Polish_D 14.3817 3 [1,] Russian_D 11.4167 [2,] Polish_D 12.1632 [3,] Russian 12.2554 4 [1,] Hungarians 15.1674 [2,] Slovenian 15.3872 [3,] German_D 20.8246 5 [1,] FIN 14.6391 [2,] Finnish_D 18.5119 [3,] Slovenian 19.647 6 [1,] Mixed_Slav_D 13.0183 [2,] Hungarians 14.1755 [3,] Polish_D 14.3841 7 [1,] Polish_D 5.3431 [2,] Mixed_Slav_D 6.896 [3,] Russian_D 12.79 8 [1,] Russian_D 6.5072 [2,] Mixed_Slav_D 8.2488 [3,] Russian 9.4432 9 [1,] Hungarians 9.6005 [2,] Polish_D 12.0513 [3,] Mixed_Slav_D 12.4813 10 [1,] Polish_D 12.7041 [2,] Mixed_Slav_D 14.2994 [3,] Hungarians 15.3044 11 [1,] FIN 9.2743 [2,] Finnish_D 15.7954 [3,] German_D 17.6308 12 [1,] Finnish_D 10.4971 [2,] FIN 13.3701 [3,] Polish_D 17.3516 13 [1,] Finnish_D 11.8036 [2,] Polish_D 15.7074 [3,] Mixed_Slav_D 16.0502 14 [1,] Hungarians 11.1875 [2,] Polish_D 13.1533 [3,] Slovenian 14.7009 15 [1,] German_D 17.2096 [2,] Swedish_D 17.5679 [3,] N._European 17.7019 16 [1,] Slovenian 7.1437 [2,] Hungarians 10.1812 [3,] German_D 12.4577 17 [1,] Hungarians 11.6839 [2,] Slovenian 13.8442 [3,] Balkans_D 15.031 18 [1,] Mixed_Slav_D 8.6327 [2,] Russian_D 8.6937 [3,] Polish_D 11.1193 19 [1,] Mixed_Slav_D 8.2442 [2,] Polish_D 9.2166 [3,] Russian_D 13.4264 20 [1,] Finnish_D 10.6054 [2,] FIN 16.6364 [3,] Russian 21.6142 21 [1,] Mixed_Slav_D 18.1396 [2,] Russian_D 19.6402 [3,] Belorussian 19.7919 22 [1,] Russian_D 10.219 [2,] Mixed_Slav_D 11.2899 [3,] Russian 11.7717
Polish_D = 11
Russian_D = 8
Hungarians = 7
FIN = 5
German_D = 5
Slovenian = 5
Finnish_D = 5
Russian = 4
Swedish_D = 2
Belorussian = 1
Balkans_D = 1
N. European = 1
And by admixture:
(Stalskoe and Urkarah are Dagestani)Code:1. 34% Lithuanians + 66% Norwegian_D 5.6864 2. 15.1% Lezgins + 84.9% Russian_D 4.7664 3. 40.6% Belorussian + 59.4% Finnish_D 5.218 4. 47.3% French_D + 52.7% Russian 11.1491 5. 85.2% FIN + 14.8% Naidu 6.0881 6. 19.7% Makrani + 80.3% Polish_D 5.6076 7. 74% Belorussian + 26% French_D 2.9759 8. 7% Moroccans + 93% Russian_D 4.139 9. 25.5% French + 74.5% Mixed_Slav_D 1.8663 10. 45.7% French_D + 54.3% Lithuanian_D 4.9695 11. 75% Finnish_D + 25% French_Basque 6.2939 12. 59.6% Russian + 40.4% Swedish_D 4.4612 13. 12.5% Bedouin + 87.5% Finnish_D 6.3979 14. 57.7% Lithuanians + 42.3% Spaniards 3.3127 15. 20.1% Iranian_D + 79.9% Swedish_D 8.4196 16. 26% FIN + 74% Slovenian 2.4918 17. 68% Polish_D + 32% Stalskoe 4.161 18. 74.9% Lithuanians + 25.1% Urkarah 3.5821 19. 40.6% Lithuanian_D + 59.4% Slovenian 4.1395 20. 87.8% Finnish_D + 12.2% Lezgins 4.8784 21. 73.9% Belorussian + 26.1% Kurd 7.1304 22. 73.1% Lithuanians + 26.9% Urkarah 4.0947
5 is the most amusing one.
Single Population Sharing (Eurogenes)
1 Estonian_Polish 4.36
2 Russian_Smolensk 4.88
3 Southwest_Russian 5.32
4 Belorussian 5.78
5 Lithuanian 5.92
| Thumbs Up/Down |
| Received: 137/0 Given: 28/0 |
Are both your parents tested? I found that the Oracle results based on the average values of my mom and dad's v3 K=12 components were more in line with my known ancestry. The same can be applied to siblings. I am not sure if anyone has tested 4 grandparents, but this, in theory, would help refine the Oracle results even further for an individual. The benefits of having a larger sample size. The population averages are simply extensions of this. Helps to reduce the possible effects of ordinary individual variation. Assuming a relatively homogeneous population.
My top Oracle prediction, based on the average of my mom and dad's values:
[1,] "16.3% Georgians + 83.7% Iraq_Jews" "1.8684"
And, you can then try mapping the "mix," to see if you can make sense of it from a different perspective. The "X" marks the spot where other analyses have suggested my ancestral origins lie (McDonald, Population Finder, etc.). Tbilisi was used for the Georgian population, and Baghdad for the Iraqi Jewish population. As one or both of these locations may not accurately capture the average geographical origins of the two population samples in question, there is a degree of error which certainly must be allowed for. The arrows represent (at least in part) that potential error. And, given that the error appears to be one of latitude, rather than longitude, and the Georgian placement, north to south, does not leave much room for adjustment, I reckon the error lies with the placement of the Iraqi Jews. They are too far to the south. But, either way, it is certainly in the ballpark. If your top "mix" predictions are within a reasonable distance of one another, you can repeat this for as many mix combinations as there are, and then determine the average of these points.
There are currently 9 users browsing this thread. (0 members and 9 guests)
 Posting Permissions
Posting Permissions
")


 Reply With Quote
Reply With Quote


Bookmarks